IBC Show VOD

Provenance – what can we trust? Results of C2PA proof of concept test undertaken by the BBC


Reports

Technical Papers 2024 Session: 5G Case Studies – public network slicing trials and striving for low latency
Reports

Technical Papers 2024 Session: Advances in Video Coding – encoder optimisations and film grain

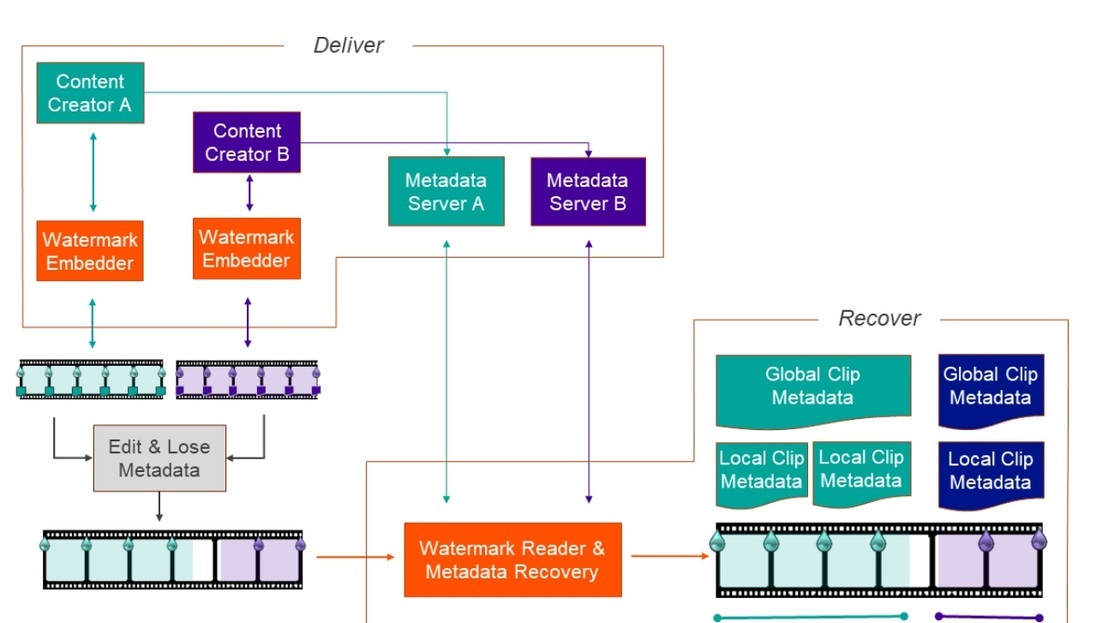
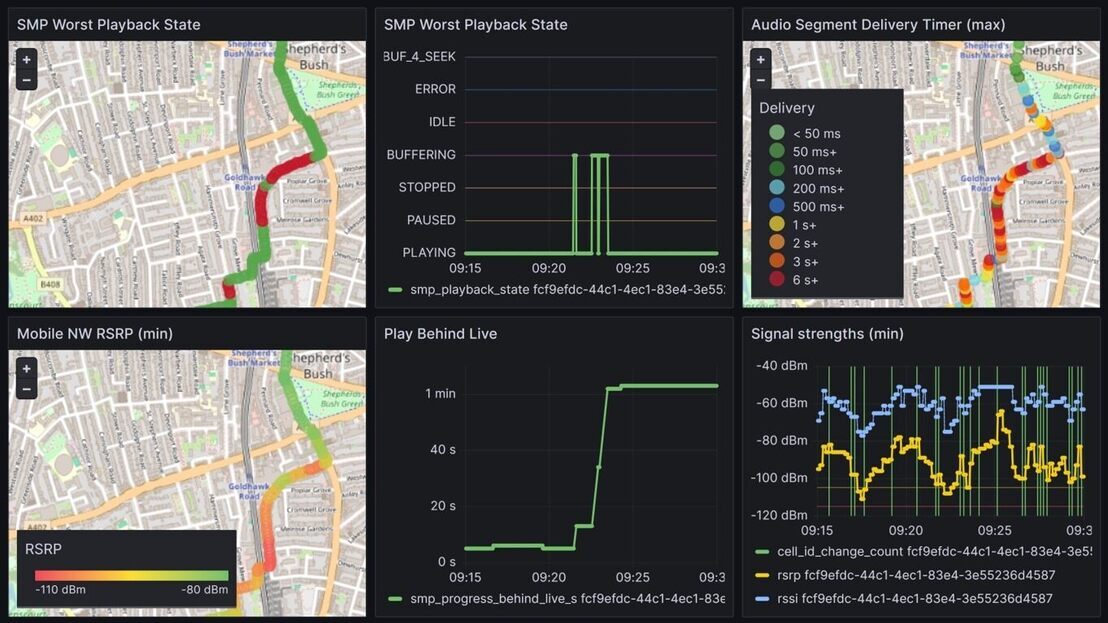
Reports