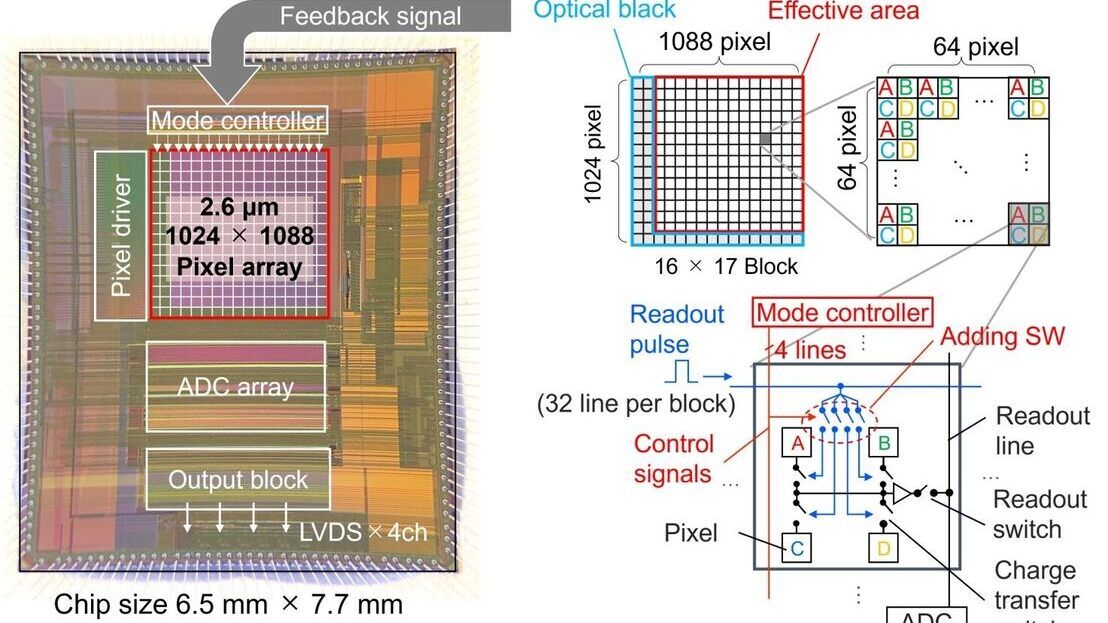
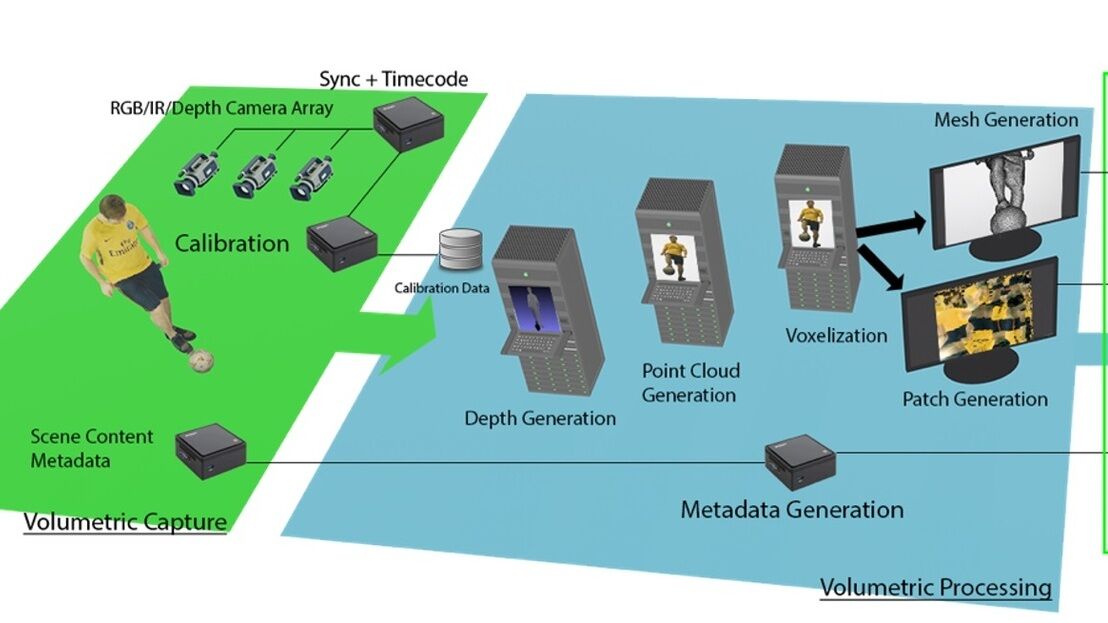
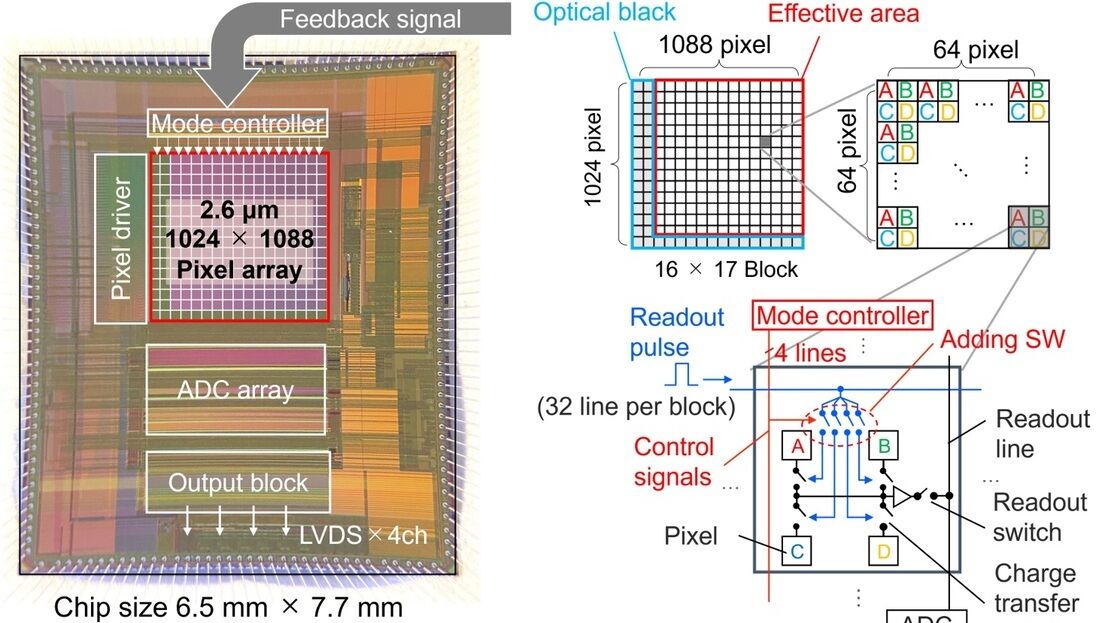
This paper introduces a generative 3D video conferencing system using pre-trained Neural Radiance Field (NeRF) models for high-fidelity 3D head reconstruction and real-time rendering.
Video conferencing, is the most demanding form of video communication in terms of real-time requirements and it remains a challenge to maintain quality in weak network conditions. Traditional block-based encoding video conferencing systems can experience freezing and significant degradation when bandwidth is extremely low or network conditions deteriorate suddenly. Recent advancements in 3D facial representation offer novel promising solutions for video conferencing under weak network conditions.
This paper introduces...
Exclusive Content
This article is available with a Technical Paper Pass
Opportunities for emerging 5G and wifi 6E technology in modern wireless production
This paper examines the changing regulatory framework and the complex technical choices now available to broadcasters for modern wireless IP production.
Leveraging AI to reduce technical expertise in media production and optimise workflows
Tech Papers 2025: This paper presents a series of PoCs that leverage AI to streamline broadcasting gallery operations, facilitate remote collaboration and enhance media production workflows.
Automatic quality control of broadcast audio
Tech Papers 2025: This paper describes work undertaken as part of the AQUA project funded by InnovateUK to address shortfalls in automated audio QC processes with an automated software solution for both production and distribution of audio content on premises or in the cloud.
Demonstration of AI-based fancam production for the Kohaku Uta Gassen using 8K cameras and VVERTIGO post-production pipeline
Tech Papers 2025: This paper details a successful demonstration of an AI-based fancam production pipeline that uses 8K cameras and the VVERTIGO post-production system to automatically generate personalized video content for the Kohaku Uta Gassen.
EBU Neo - a sophisticated multilingual chatbot for a trusted news ecosystem exploration
Tech Papers 2025: The paper introduces NEO, a sophisticated multilingual chatbot designed to support a trusted news ecosystem.
Registered users only: Login