Home
Watch
IBC2025
Log in
Enter keywords
Submit search
Home
Watch
IBC2025
Log in
Ad-Tech
Ad-Tech
Dynamic Ad Insertion
Personalisation
Programmatic & Addressable Platforms
T-Commerce
Artificial Intelligence
Artificial Intelligence
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
Connective Tech
Connective Tech
5G
6G
Cloud
Digital Audio Workstation
Edge Computing
IP Workflows
Network Slicing
Esports & Gaming
Esports & Gaming
Esports Broadcast & Distribution
Esports Monetisation
Live Esports Production
TV & Cloud Gaming
IBC Show
IBC Show
IBC2024
IBC2023
IBC2025
Immersive Tech
Immersive Tech
AR
Immersive Audio
Metaverse
MR
Spatial Computing
Volumetric Video
VR
XR
OTT & Streaming
OTT & Streaming
AVOD
CDNs
FAST
SVOD
TVOD
People & Purpose
People & Purpose
Acquisition & Retention
Diversity, equity & inclusion
Skills & Training
Sustainability
Virtual Production
Virtual Production
Camera Tracking
Worldbuilding
Motion Capture & Performance
Rendering & Compositing
Robotic Cameras
Enter keywords
Submit search
Accelerating Innovation
IBC Technical Papers
Topics:
IBC Accelerators
IBC Technical Papers
Intellectual property
Choose a topic
IBC Accelerators
IBC Technical Papers
Intellectual property
View other themes:
CHOOSE THEME
AD-TECH
ARTIFICIAL INTELLIGENCE
CONNECTIVE TECH
ESPORTS & GAMING
IBC SHOW
IMMERSIVE TECH
OTT & STREAMING
PEOPLE & PURPOSE
VIRTUAL PRODUCTION
Features
IBC Technical Papers: AI, XR and media provenance among the 2024 highlights
News
IBC2024 Technical Papers: Submissions Open
News
IBC Technical Papers: Inside the workings of the committee and conference
Reports
Technical Papers 2024 Session: Streaming – the view from each end
IBC Show VOD
Technical Papers: Advances in video coding and processing
IBC Show VOD
Technical Papers: 5G technology - convergence with broadcast
IBC Show VOD
XR, AI, 5G and sustainability advances top IBC2024 Technical Papers
Reports
IBC2024 Tech Papers: 3GPP SA4 - The media and XR powerhouse for 5G and 6G
Reports
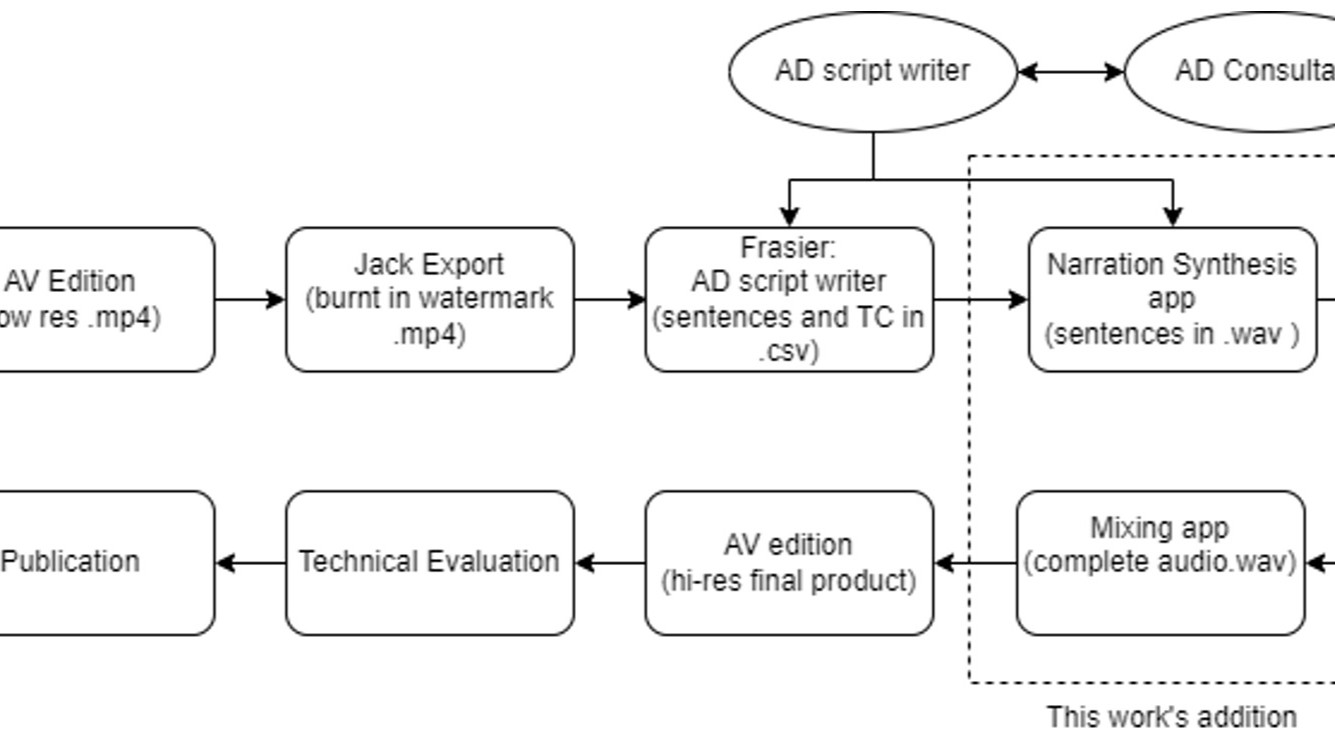
IBC2024 Tech Papers: AI for audio description: A natural voice for accessibility
Reports
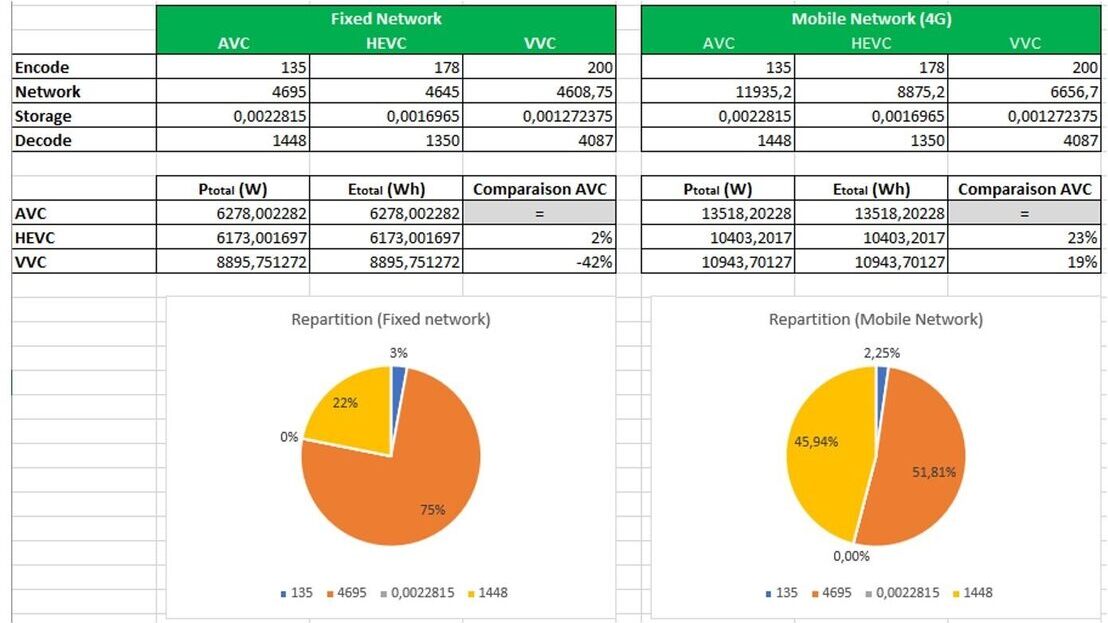
IBC2024 Tech Papers: An Efficient and Sustainable End-to-End Video Streaming Architecture
Reports
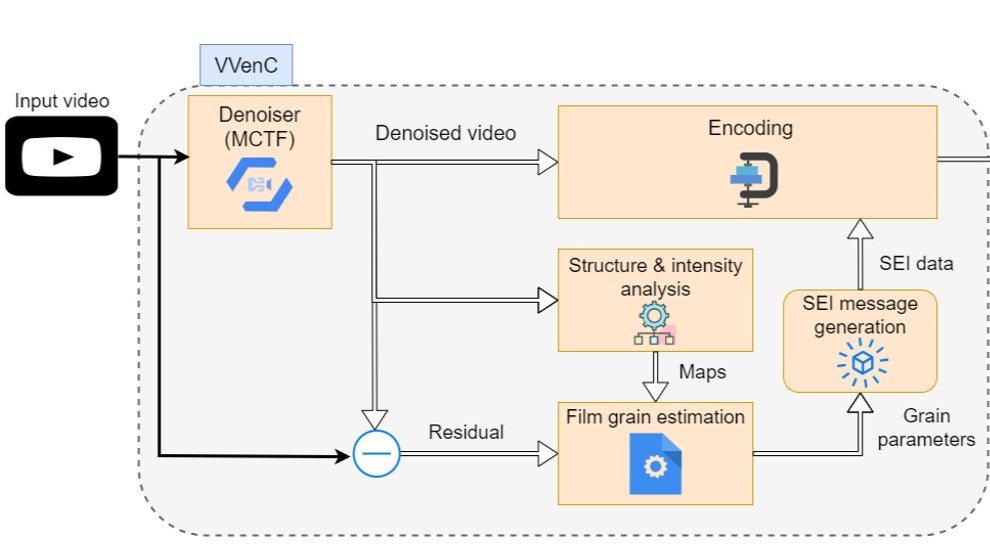
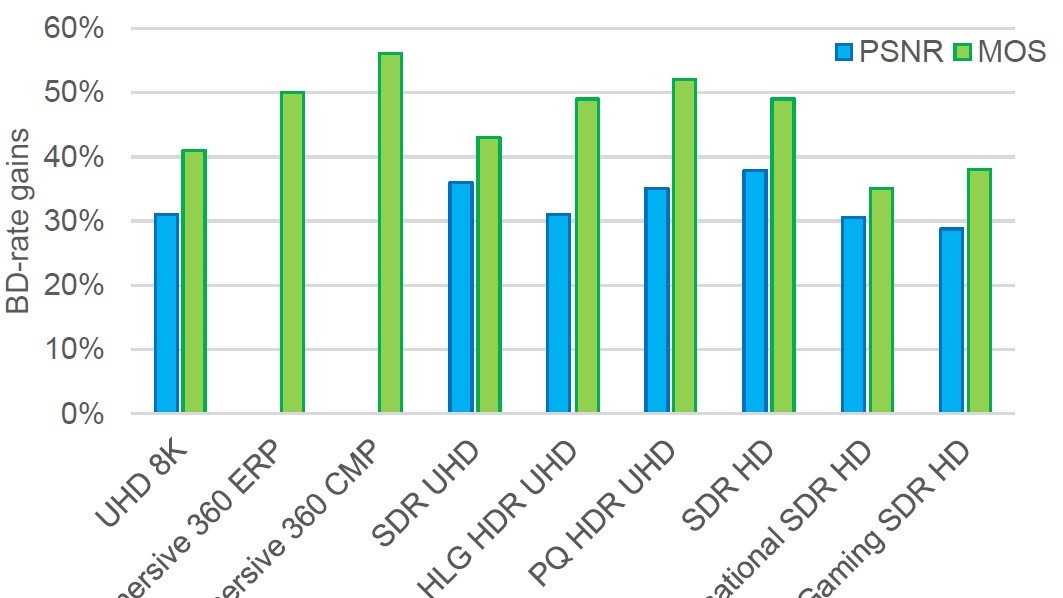
IBC2024 Tech Papers: Enhancing Film Grain Coding in VVC: Improving Encoding Quality and Efficiency
Reports
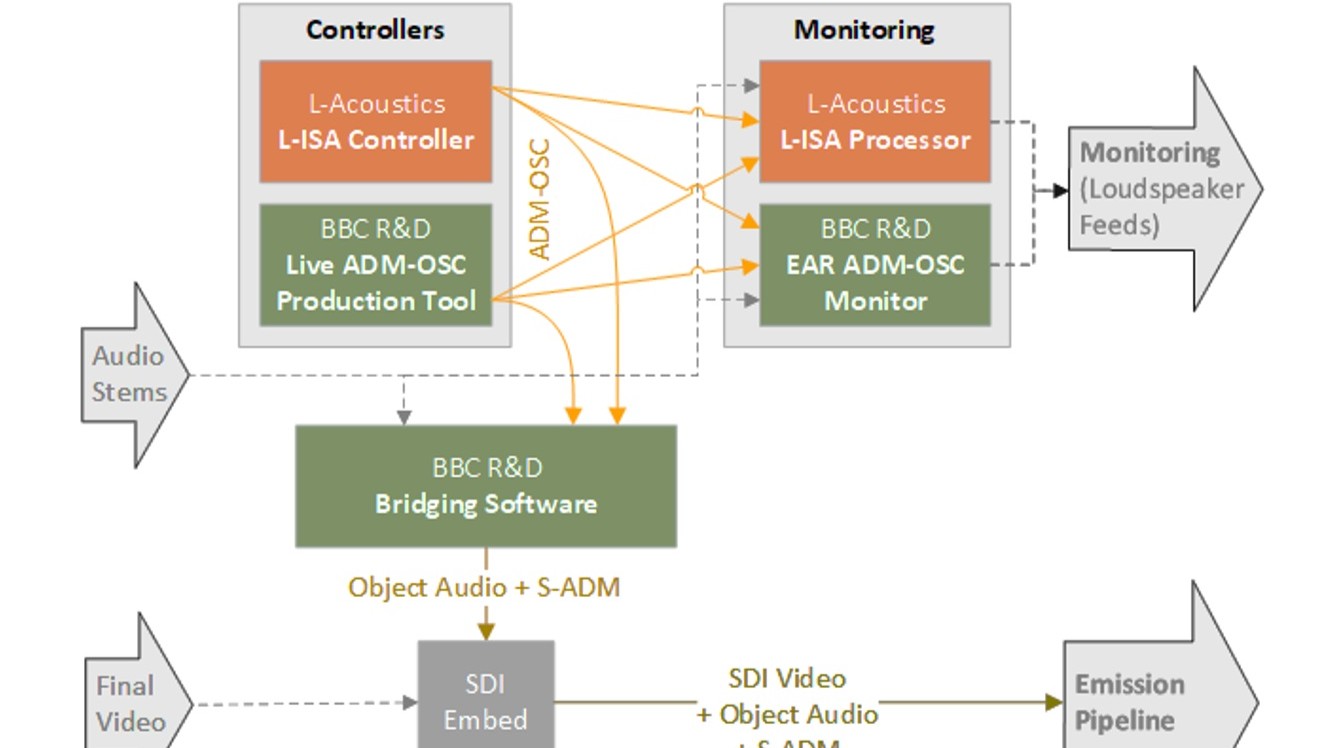
IBC2024 Tech Papers: Live Production using the Audio Definition Model at the Eurovision Song Contest 2023
Reports
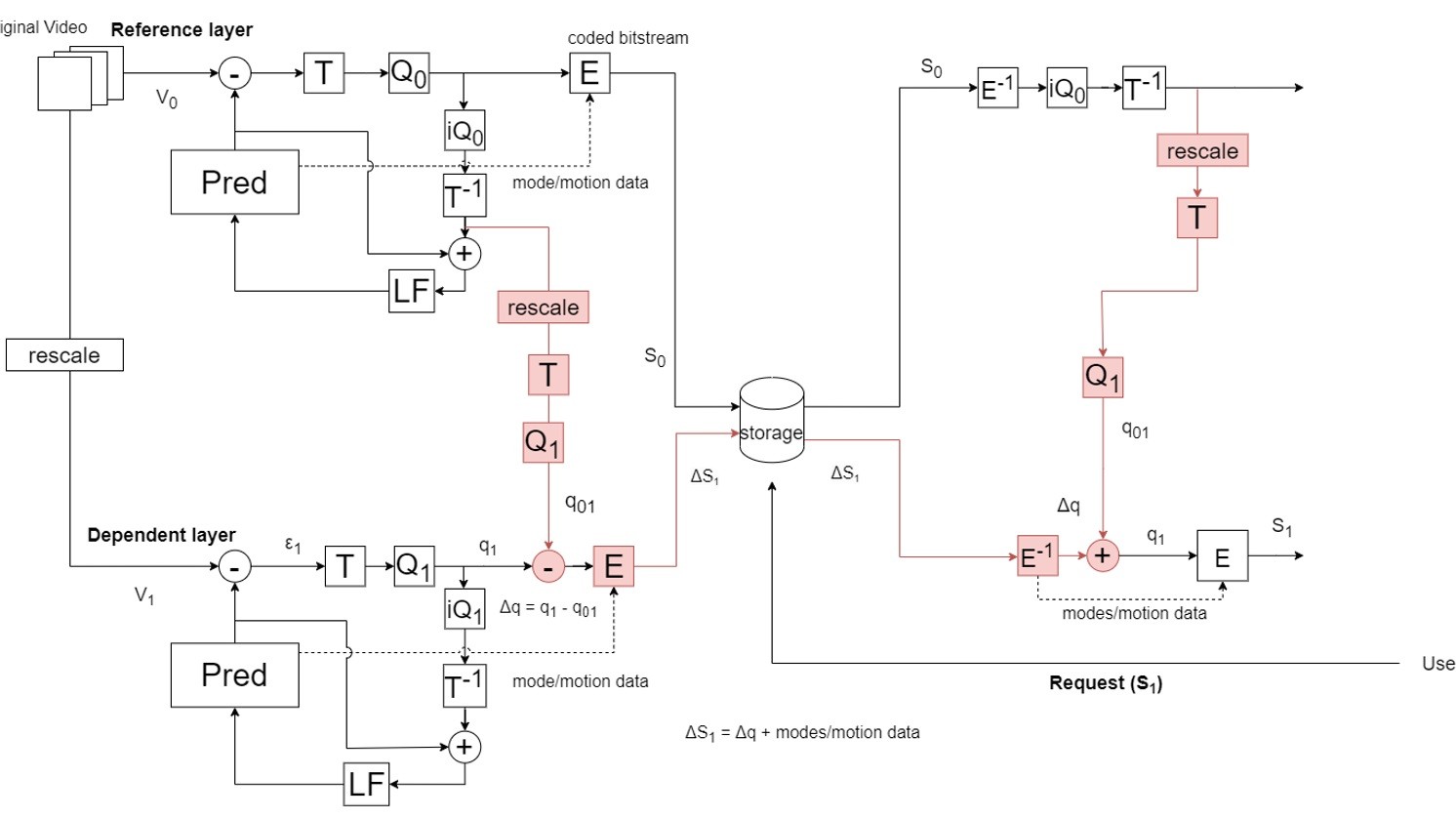
IBC2024 Tech Papers: Novel coding methods for storage bit-cost, transcoding complexity, and transmission efficiency trade-off optimization of multi-profile video delivery system
Reports
IBC2024 Tech Papers: “Quantitative assessment of film grain similarity: an objective model”
Reports
IBC2024 Tech papers: Ready for deployment: VVC’s adoption and interoperability status