This study describes the development and implementation of an AI-based natural voice synthesis and automated mixing workflow for audio description (AD) in Brazilian television drama content, with a real demonstration case of success.
The evolving landscape of media consumption underscores the crucial need for inclusivity, particularly for those with visual impairments. Audio description (AD) plays an indispensable role in making media accessible, providing a verbal representation of visual content that allows visually impaired individuals to experience films, television, and live performances in meaningful ways. As described by Audio Description provides narration of the visual elements - action, costumes, settings, and the like - of theatre, television/film, museum exhibitions, and other events. The technique allows patrons who are blind or have low vision the opportunity to experience arts events more completely - the visual is made verbal. AD is a kind of literary art form, a type of poetry. Using words that are succinct, vivid, and imaginative, describers try to convey the visual image to people who are blind or have low vision” (J. Snyder).
However, traditional methods of producing audio descriptions are fraught with challenges, including high production costs and significant time demands, which have historically limited the accessibility and timeliness of such services. According to the 2010 data from the Brazilian Institute of Geography and Statistics (IBGE) (MEC), there are approximately 6.5 million people in Brazil with significant or severe visual impairments. This statistic is supported by findings from the 2019 National Health Survey (PNS) (IBGE), which indicates that 3.4% of the population, or around 3.978 million people, experience some form of visual impairment. It is crucial to recognize that audio description benefits not only those who are completely blind but also those with partial and severe vision loss. Additionally, other groups, including individuals with intellectual disabilities and learning disorders, can greatly benefit from audio description as it serves as an alternative sensory channel that aids in quicker and more effective comprehension of visual content.
This paper offers...
You are not signed in.
Only registered users can view this article.

IET announce Best of IBC Technical Papers
The IET have announced the publication of The best of IET and IBC 2024 from IBC2024, once again showcasing the groundbreaking research presented through the papers. The papers have been selected by IBC’s Technical Papers Committee for being novel, topical, analytical and well-written and which have the potential to make a significant impact upon the media industry. 327 papers were submitted this year, and after a rigorous selection process this publication features the ten papers deemed by the judges to be the best.

Technical Papers 2024 Session: 5G Case Studies – public network slicing trials and striving for low latency
In this session from IBC2024, Telestra Broadcast Service and the BBC present their work 5G Case Studies as part of the IBC Technical Papers.
Technical Papers 2024 Session: AI in Production – training and targeting
In this session from IBC2024, three authors from NHK, Viaccess-Orca and European Broadcasting Union present their work on the application of AI to media production as part of the IBC Technical Papers.
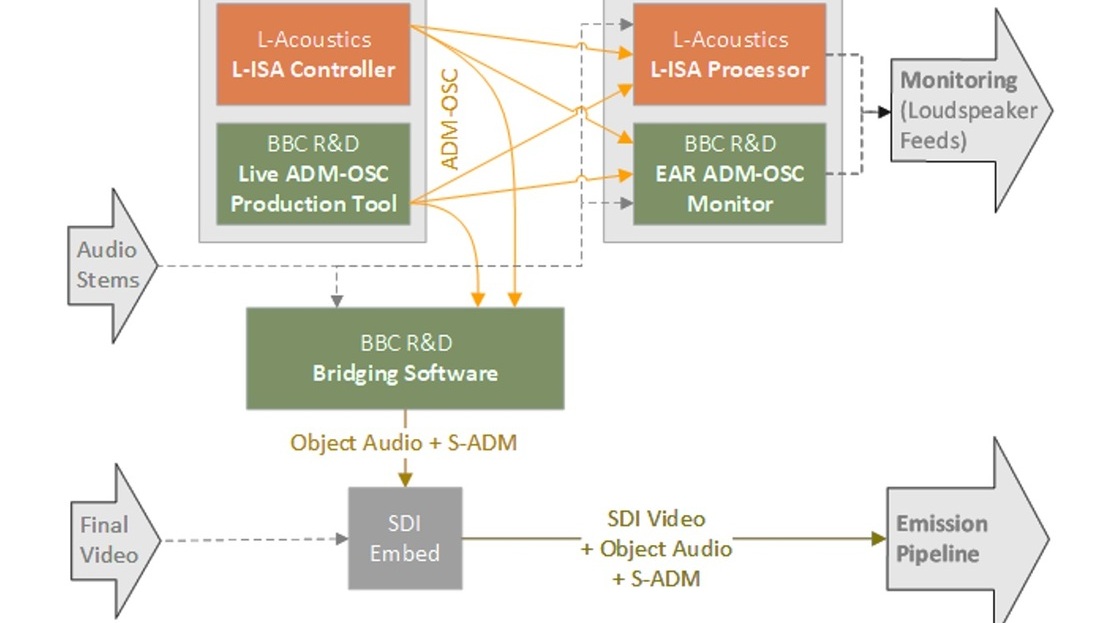
Technical Papers 2024: Audio & Speech – advances in production
In this session from IBC2024, two authors present their work on Audio Description and implementing Audio Definition Model as part of the IBC Technical Papers.

Technical Papers 2024 Session: Advances in Video Coding – encoder optimisations and film grain
In this session from IBC2024, IMAX, MediaKind, Fraunhofer HHI and Ericsson present their work on video coding, as part of the IBC Technical Papers
Registered users only: Login