This paper explores architectural strategies, resources allocation guidelines and cloud-native workflows that are time-tested to support mega-scale live streams and examines common failure scenarios and anti-patterns, identifies infrastructure bottlenecks and proposes fallback strategies to enhance resilience and reliability at massive concurrency scales.
The rise of video streaming platforms has revolutionized the way that the world consumes media today. This modern streaming landscape is characterized by a relentless demand for scalable, high-performance applications that can accommodate millions of concurrent users while maintaining the highest-quality user experiences.
When it comes to live sports streaming, unpredictable traffic patterns during a game can often overwhelm even the most well-designed systems. Reasons for this being: - The inadequate capabilities of traditional autoscalers to keep pace with a traffic spike; - Infrastructure limitations that are apparent only at mega-scale; and - Suboptimal system configurations.
This paper offers the following solutions...
You are not signed in.
Only registered users can view this article.

IET announce Best of IBC Technical Papers
The IET have announced the publication of The best of IET and IBC 2024 from IBC2024, once again showcasing the groundbreaking research presented through the papers. The papers have been selected by IBC’s Technical Papers Committee for being novel, topical, analytical and well-written and which have the potential to make a significant impact upon the media industry. 327 papers were submitted this year, and after a rigorous selection process this publication features the ten papers deemed by the judges to be the best.

Technical Papers 2024 Session: 5G Case Studies – public network slicing trials and striving for low latency
In this session from IBC2024, Telestra Broadcast Service and the BBC present their work 5G Case Studies as part of the IBC Technical Papers.
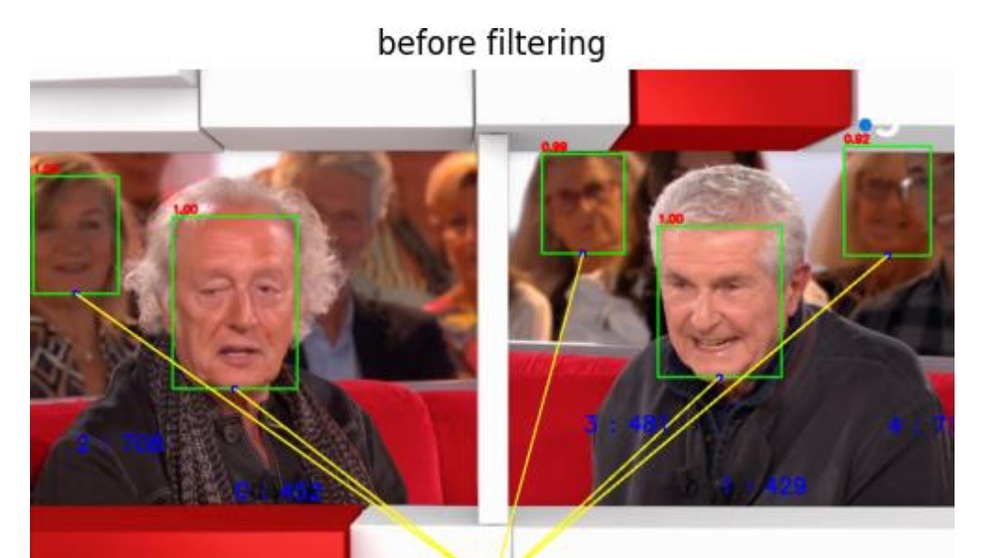
Technical Papers 2024 Session: AI in Production – training and targeting
In this session from IBC2024, three authors from NHK, Viaccess-Orca and European Broadcasting Union present their work on the application of AI to media production as part of the IBC Technical Papers.
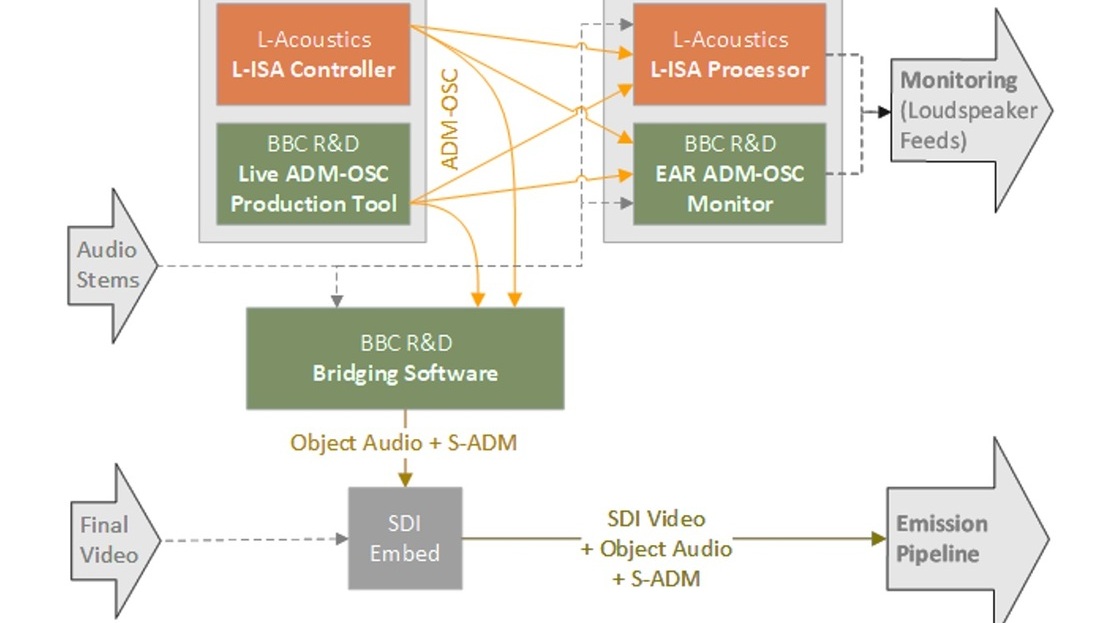
Technical Papers 2024: Audio & Speech – advances in production
In this session from IBC2024, two authors present their work on Audio Description and implementing Audio Definition Model as part of the IBC Technical Papers.

Technical Papers 2024 Session: Advances in Video Coding – encoder optimisations and film grain
In this session from IBC2024, IMAX, MediaKind, Fraunhofer HHI and Ericsson present their work on video coding, as part of the IBC Technical Papers
Registered users only: Login