This paper explores how broadcast media organisations can utilize systems that automatically label news articles.
Broadcast media organisations produce many news scripts every day for dissemination as content. Such text data is often reused in the process of producing TV programmes and web news. To efficiently utilise this much data, it is necessary to accurately attach metadata such as labels that indicate the content of the text. However, manually assigning labels takes an enormous amount of time and effort. With the aim of reducing costs, we have developed a system that automatically labels news articles. A major challenge in the multi-label text classification task in the news domain is known as ‘imbalanced learning.’ We proposed a novel...
You are not signed in.
Only registered users can view this article.

IET announce Best of IBC Technical Papers
The IET have announced the publication of The best of IET and IBC 2024 from IBC2024, once again showcasing the groundbreaking research presented through the papers. The papers have been selected by IBC’s Technical Papers Committee for being novel, topical, analytical and well-written and which have the potential to make a significant impact upon the media industry. 327 papers were submitted this year, and after a rigorous selection process this publication features the ten papers deemed by the judges to be the best.

Technical Papers 2024 Session: 5G Case Studies – public network slicing trials and striving for low latency
In this session from IBC2024, Telestra Broadcast Service and the BBC present their work 5G Case Studies as part of the IBC Technical Papers.
Technical Papers 2024 Session: AI in Production – training and targeting
In this session from IBC2024, three authors from NHK, Viaccess-Orca and European Broadcasting Union present their work on the application of AI to media production as part of the IBC Technical Papers.
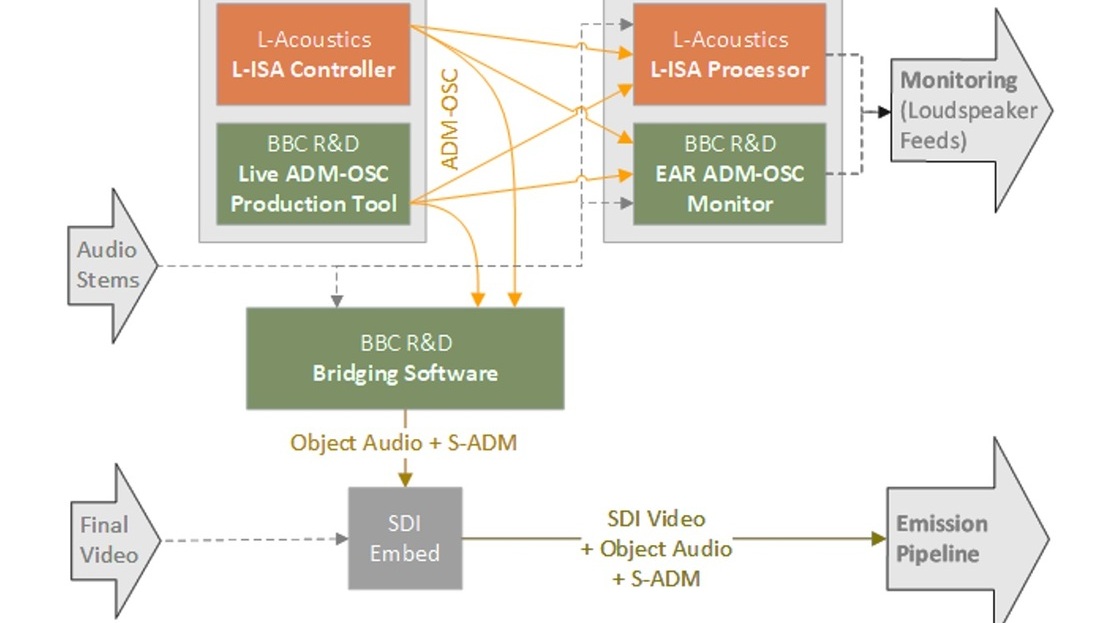
Technical Papers 2024: Audio & Speech – advances in production
In this session from IBC2024, two authors present their work on Audio Description and implementing Audio Definition Model as part of the IBC Technical Papers.

Technical Papers 2024 Session: Advances in Video Coding – encoder optimisations and film grain
In this session from IBC2024, IMAX, MediaKind, Fraunhofer HHI and Ericsson present their work on video coding, as part of the IBC Technical Papers
Registered users only: Login