Home
Watch
IBC2025
Log in
Enter keywords
Submit search
Home
Watch
IBC2025
Log in
Accelerating Innovation
Accelerating Innovation
IBC Accelerators
IBC Technical Papers
Intellectual property
Artificial Intelligence
Artificial Intelligence
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
Connective Tech
Connective Tech
5G
6G
Cloud
Digital Audio Workstation
Edge Computing
IP Workflows
Network Slicing
IBC Show
IBC Show
IBC2024
IBC2023
IBC2025
Immersive Tech
Immersive Tech
AR
Immersive Audio
Metaverse
MR
Spatial Computing
Volumetric Video
VR
XR
OTT & Streaming
OTT & Streaming
AVOD
CDNs
FAST
SVOD
TVOD
People & Purpose
People & Purpose
Acquisition & Retention
Diversity, equity & inclusion
Skills & Training
Sustainability
Production
Production
Audio Tech
Camera Tech
Content Acquisition
IP Production
LED Volumes
Live Production
Outside Broadcast (OB)
Remote Production
Sports Production
Storytelling
Studio Production
Virtual Production
Virtual Production
Camera Tracking
Worldbuilding
Motion Capture & Performance
Rendering & Compositing
Robotic Cameras
Enter keywords
Submit search
Artificial Intelligence
AI Post-Production
Topics:
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
Choose a topic
AI Audio
AI Post-Production
Deep Fakes & Digital Replicas
Ethics
GenAI
Machine Learning
Scraping & Training
View other themes:
CHOOSE THEME
ACCELERATING INNOVATION
CONNECTIVE TECH
IBC SHOW
IMMERSIVE TECH
OTT & STREAMING
PEOPLE & PURPOSE
PRODUCTION
VIRTUAL PRODUCTION
Features
NAB show review: Tariffs, technology and legacy business in the spotlight
Read now
Features
NAB show review: Tariffs, technology and legacy business in the spotlight
Interview
NAB 2025: Jacques Le Mancq: “Multicast ABR becoming mainstream”
Interview
Enginelab and the new breed of cloud post-producer
Features
NAB preview: Agentic AI poised to steal the show
Interview
Kickstart Day 2025: IP, cloud and AI top priority list for broadcasters
News
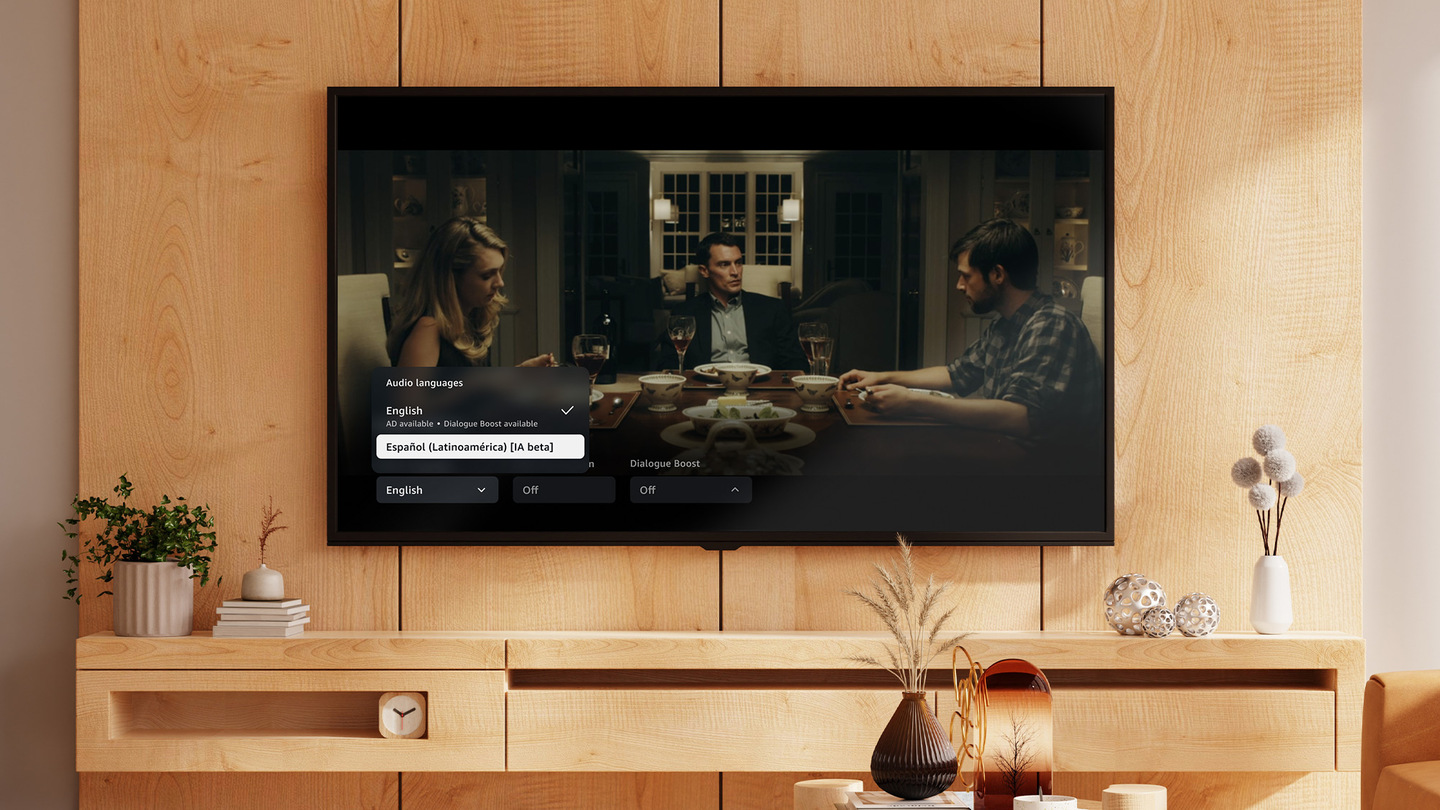
Prime Video launches AI dubbing pilot programme
Features
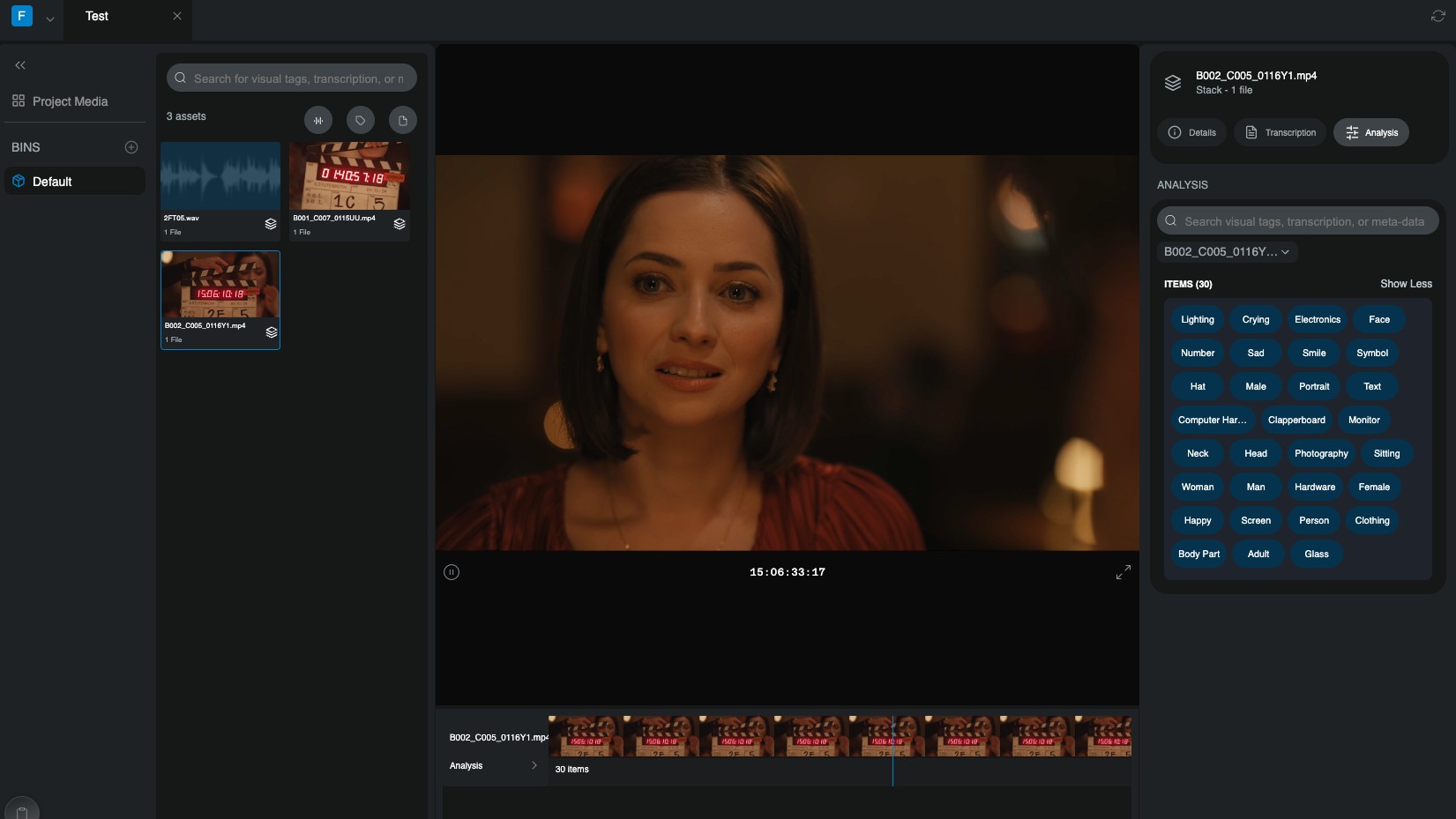
Wary eye on AI: Post cautiously embraces new generation of tools
Features
Behind the scenes: Editing Sugar Babies and By Design in Premiere
Features
Dramatic closure of Technicolor VFX has been decades in the making
News
DNEG Group’s Brahma acquires AI developer Metaphysic
News
Flawless launches AI-powered editing tool DeepEditor
Interview
ISE 2025: Broadcasters and proAV “want the same thing” from IP-based video
Interview
ISE 2025: “They don’t ask what can we do with your technology they ask what can’t we do with your technology”
Features
AI and live production: Experimentation giving way to well-defined applications
News
Sylvester Stallone invests in film and TV AI platform Largo.ai
Features
ISE2025: Putting the art into artificial intelligence
Features
Data-driven audio: Why AI is sounding great for everyone
More



.jpg)








.jpg)
.jpg)

